



There was a time, brief and overly PowerPointed, when the Customer Data Platform (CDP) was sold as the answer to everything: clean data, unified profiles, cross-channel orchestration, even internal peace treaties between marketing and IT.
One platform. One profile. One truth.
And then reality showed up.
Not with a bang, but with two CDPs.
The CDP Institute’s 2024 Member Survey reports an average of 2.1 CDPs per company, and Simon Data observes a drop from 2.9 to 2.1 based on that data. That might look like consolidation (down from 2.9 the year before), but it isn’t necessarily simplification. Teams weren’t aiming for complexity to begin with. They were responding to gaps in their requirements, and with time equaling money, they often grabbed whatever they could to get the job done.
One CDP lacked the flexibility they needed, and layering in a second (or a third) became the workaround that stuck. So teams are keeping the ones that serve their needs, and ditching the rest.
Stack drift doesn’t happen in a vacuum. It’s the natural result of teams pulling in different directions, each adopting tools that reflect their own priorities and ways of working. And that split maps almost perfectly to what David Chan has laid out in the Dual Zone model: a Data Zone built for identity, modeling, and governance, and an Engagement Zone for personalization, journey logic, and activation.
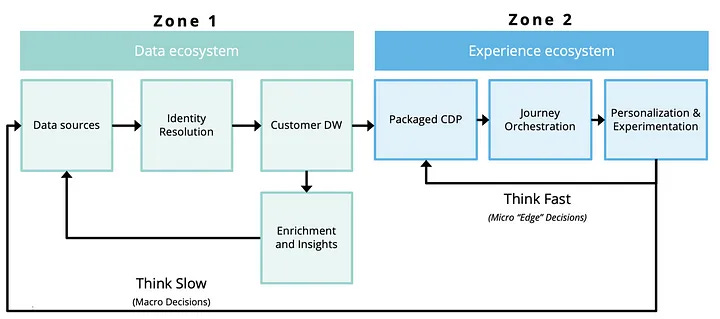
These setups aren’t new. They’ve been evolving for years, usually out of necessity and without the owners knowing what to call it. The data team anchors on quality and governance. Marketing wants segmentation and speed. Add a regional or brand-specific stack already in play, and suddenly you’ve got a Multi-CDP organization. Whether you intended to or not.
In one stack, you’ll see a CDP focused on identity resolution. Elsewhere, it might be tagging or orchestration that dominates. Sometimes, it’s just about pushing segments into ad platforms because the other systems move too slowly. Each of these tools was brought in to solve a specific need, whether it was unifying profiles, improving real-time responsiveness, or enabling marketing teams to launch campaigns without waiting for a new data pipeline to be configured.
Derek Slager of Amperity, during my podcast with him earlier this year, put it plainly from what he is seeing in the market:
“You see identity as a technical challenge, but it’s also a political one. It defines who gets to act on the data, and when. And if you get that wrong, good luck making anything else work.”
You don’t get fragmentation because someone planned poorly. You get it because the business outpaced the operating model, and the stack tried to catch up.
Additionally, on meeting requirements within companies, Neill Brookman said to me while giving a demo of MetaRouter:
“I don’t care what the vendor calls it. If I need real-time data for personalization and that’s not in my CDP, I’m going to go around it. That’s how ‘shadow CDPs’ are born.”
What this series will explore
The Multi-CDP Reality picks up where CDP Reboot and Contextual CDPs left off. This series takes a closer look at what’s really been built in practice and how organizations ended up with the stacks they now rely on.
We’ll explore how CDP setups tend to reflect the zones they serve, some optimized for data, others for delivery. We’ll dig into how composable stacks often drift into multi-CDP territory. We’ll spend time on the friction that emerges when ownership isn’t clearly defined, especially across marketing and data teams. And we’ll look at what vendors like Hightouch and Snowplow are now quietly admitting by stepping into real-time engagement.
Most of all, we’ll ask a better question, not
“How many CDPs do you have?”
but
“What is each one actually doing, and who is it really for?”
That’s where the real story starts. And where this series begins.